Basic Code Obfuscation

Code Obfuscation
The basic idea of code obfuscation is to transform a piece of code into a version that is functionally equivalent, but more difficult to reverse engineer. The goal is to remove all the abstractions that the developer has added in order to create a well-modularized and easy-to-maintain code.
There are several topics on which one can work: control flow, data encoding, functions, the exception system; etc.
The more code that can be transformed, the better the result. Since a compiler usually tries to produce the smallest and/or fastest code possible, making the code harder to understand will make it slower and bigger. Finding the right balance between how resistant the result is to reverse engineering and how fast or large the code is is important.
Code obfuscation techniques are a way to buy time when defending against a reverse engineer. However, it is important to remember that no obfuscation technique is completely unbreakable!
A static obfuscator creates programs that don't change when they run. Static obfuscators try to make programs harder to analyze, but they often don't work if the reverse engineer is using dynamic analysis techniques. Dynamic obfuscators change the program at runtime to make it harder to analyze.
Some obfuscators work with source code, while others work with byte- or machine code. Binary obfuscators are usually made for one or a few types of hardware. Source code obfuscators usually work with a single programming language.
Examples of Code Obfuscators
Obfuscator-LLVM
Obfuscator-LLVM is an open-source academic project born at the University of Applied Sciences Western Switzerland in 2010 that is freely available. It is based on an old version of the LLVM compiler (v4.0) and works at the intermediate representation (IR) level. Many forks are available, but their quality varies. Obfuscator-LLVM supports all the programming languages and hardware platforms supported by LLVM.
It supports a few code transformations, including code diversification, bogus control-flow insertion, instruction substitutions and control-flow flattening.
O-MVLL
O-MVLL is an open-source and free obfuscator based on LLVM that uses the new LLVM pass manager -fpass-plugin to perform native code obfuscation. It is part of the Open-Obfuscator project, which is a free and open-source obfuscator for mobile applications.
O-MVLL only supports (and will only support) the ARM 64-bit architecture and it implements various code transformations and protections: anti-hooking, arithmetic obfuscation, control-flow breaking, control-flow flattening, opaque constants and fields access, strings encoding, etc.
Tigress
Tigress is a free, but closed-source obfuscator targeting the C language. It works at source code level and supports many transformations: code virtualization and jitting, control-flow flattening, functions splitting and merging, arguments randomization, literals, data and arithmetic encoding some defenses against dynamic analysis, etc.
Code Diversification
A compiler is a tool that should always produce the same results. If you compile the same source code twice, you should get the same executable files. Code diversification is a technique that allows you to produce many programs that work the same way. It allows to implement code watermarking. This concept is also studied in the context of protecting software against large-scale attacks.
Many code transformations can be randomized in some way. Coupling these diversification techniques with a pseudorandom generator can have the following effects: the same seed will produce the same executable, while different seeds will produce different executables. As a result, it is possible to deliver an individualized executable to each user.
Here are just a few examples of code diversification for arithmetic and Boolean operations:
x *= 2; vs. x <<= 1;
x = a+1; vs. x = a + 123 - 122;
x = a + b; vs. x = -(-a -b);
x = a + b; vs. x = a - ~b - 1;
x = a ^ b; vs. x = (~a&b) | (a&~b);
x = a ^ b; vs. x = (a|b) - (a&b);Some of the above expressions are Mixed Boolean Arithmetic (MBA) expressions, which are an important category of code transformations because they are not easily simplified by automatic tools.
Control-Flow Flattening
Control-flow flattening is the process of removing structured control flow constructs such as loops, if-then-else, switch constructs, and so on. It is also called chenxification, in honor of its inventor, Chenxi Wang. The main idea is to assign each basic block to a case within a switch construct, and to wrap the switch in an infinite loop that is responsible for computing the routing between basic blocks. The figure below illustrates the effects of control flow flattening.
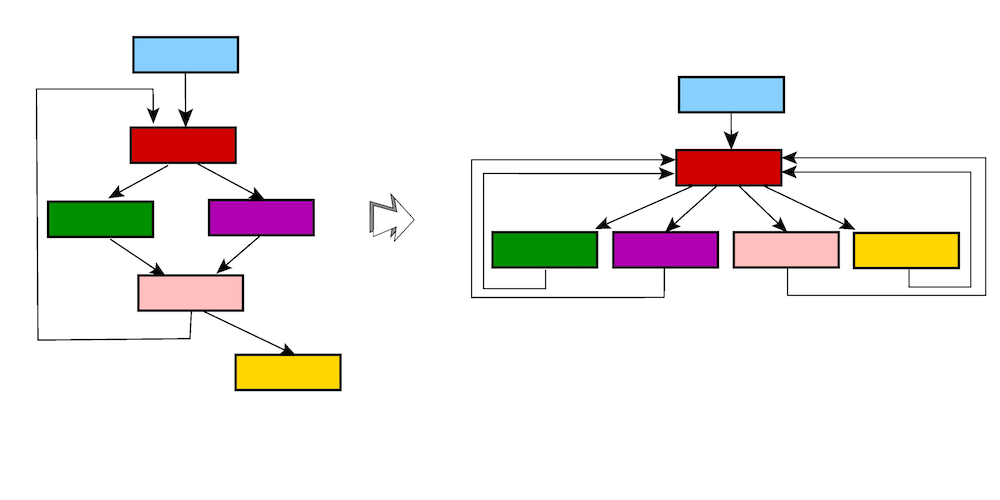
There are many ways to implement the basic block dispatching mechanism. Here are the results of a recursive implementation of the factorial function of three variants implemented by the Tigress obfuscator, namely switch dispatching, goto dispatching, and call dispatching.
The first variant, called switch dispatching, involves a routing variable called next. You can see the infinite loop and the switch construct. The routing variable is updated after each basic block is executed if the function does not return.
int fac(int x) {
int tmp ;
unsigned long next ;
next = 4;
while (1) {
switch (next) {
case 4:
if (x == 1) {
next = 3;
} else {
next = 2;
}
break;
case 3: return (1); break;
case 2: tmp = fac(x - 1); next = 1; break;
case 1: return (x * tmp); break;
}
}A second variant, called goto dispatching, relies on a jump table storing the address of each basic block. The routing variable next is then used as an index within that jump table.
int fac(int x) {
int tmp ;
unsigned long next ;
static void *jumpTab[4] = {&& lab1, && lab2, && lab3, && lab4};
next = 4;
goto *(jumpTab[next - 1]);
lab4:
if (x == 1) {
next = 3;
} else {
next = 2;
}
goto *(jumpTab[next - 1]);
lab3:
return (1);
goto *(jumpTab[next - 1]);
lab2:
tmp = fac(x - 1);
next = 1;
goto *(jumpTab[next - 1]);
lab1:
return (x * tmp);
goto *(jumpTab[next - 1]);
}A third variant, called call dispatching, replaces basic block addresses with function calls.
struct argStruct {
int tmp ;
int *x ;
int returnv ;
unsigned long next ;
};
void block_1(struct argStruct *arg ) {
arg->returnv = *(arg->x) * arg->tmp;
arg->next = 5;
return;
}
void block_2(struct argStruct *arg ) {
arg->tmp = fac(*(arg->x) - 1);
arg->next = 1;
return;
}
void block_4(struct argStruct *arg ) {
if (*(arg->x) == 1) {
arg->next = 3;
} else {
arg->next = 2;
}
return;
}
void block_3(struct argStruct *arg ) {
arg->returnv = 1;
arg->next = 5;
return;
}
int fac(int x ){
struct argStruct arg ;
static void (*jumpTab[4])(struct argStruct *arg ) =
{& block_1, & block_2,& block_3, & block_4};
arg.next = 4;
arg.x = & x;
while (1) {
if (arg.next > 4) {
return (arg.returnv);
} else {
(*(jumpTab[arg.next - 1]))(& arg);
}
}
}Bogus Control-Flow Insertion
Bogus control-flow insertion is a way to make some control flow more complex.
One idea is to add new basic blocks that contain junk or legitimate code that is never executed. Such a code transformation involves opaque predicates, which are Boolean expressions that always return the same result and cannot be optimized by the compiler. The figure below is an illustration the effects of bogus control-flow insertion.
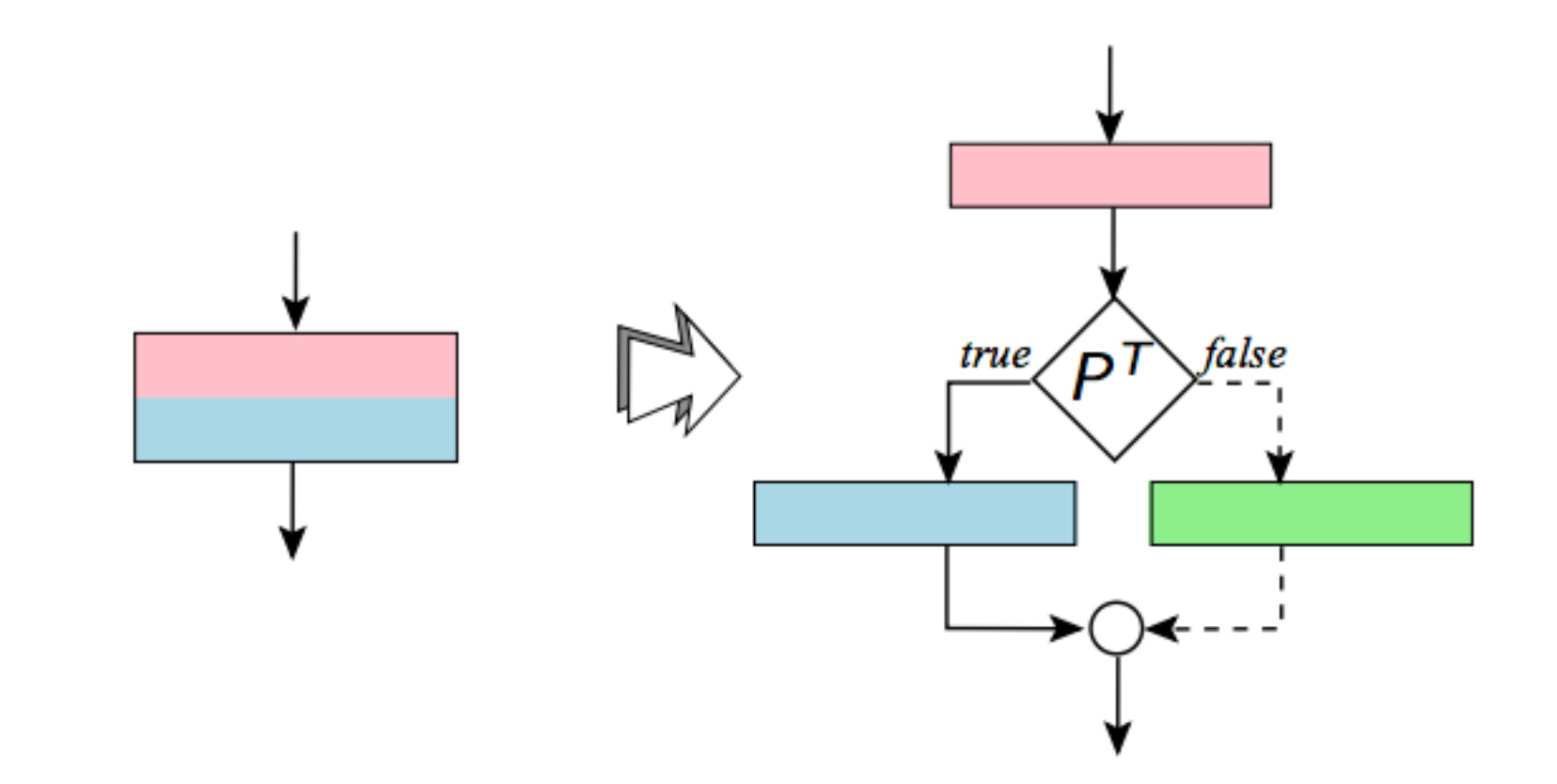
Another approach is to clone a basic block and randomly goes in the original or in the cloned version.
Data Encoding
The idea of data encoding is to replace a variable by an encoded version thereof. Many possible simple transformations; here, r is a pseudo-random value generated at obfuscation time: XOR-based masking: xx = x ^ r; addition-based masking: xx = x + r; or affine masking: xx = r1*x + r2.
Here is an example of data encoding using the Tigress obfuscator:
int main () {
int arg1 = ...
int arg2 = ...
int a = arg1;
int b = arg2;
int x = a*b;
printf("x=%i\n",x);
}is transformed into
int main () {
int arg1 = ...
int arg2 = ...
a = 1789355803 * arg1 + 1391591831;
b = 1789355803 * arg2 + 1391591831;
x = ((3537017619 * (a * b) - 3670706997 * a) - 3670706997 * b)
+ 3171898074;
printf("x=%i\n", -757949677 * x - 3670706997);
}In the next episode, I’ll cover code virtualization and tamper-proofing. Stay tuned!
Thanks for reading Crumbs of Cybersecurity! Subscribe for free to receive new posts and support my work.